


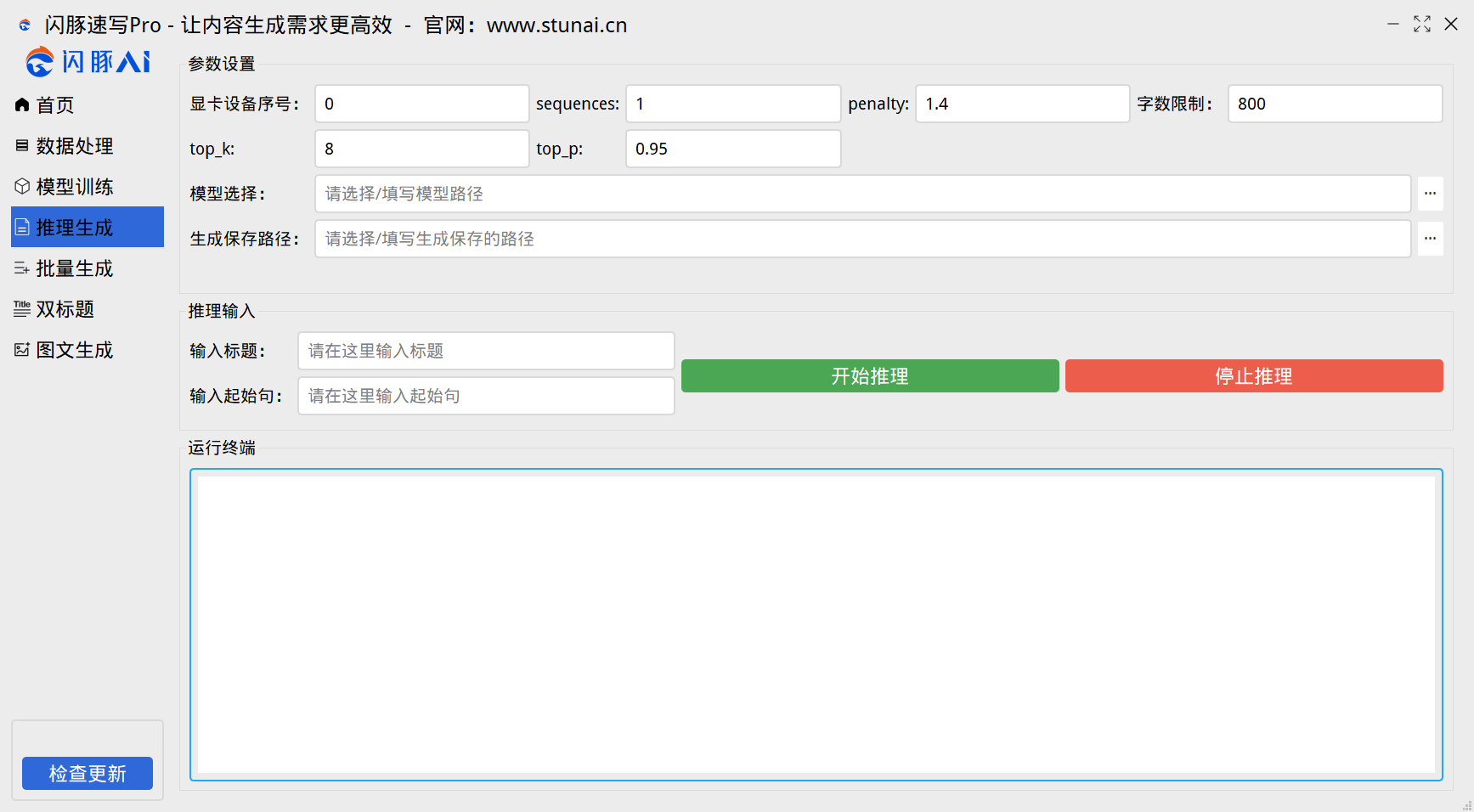
很多用户已经使用上了推理,但是想要模型生成出来的质量更好,需要根据自己的应用场景和模型质量进行调参。
下面我们来讲解一下这些参数的说明:
seqiences:表示生成的序列个数。如果设置为大于1的值,模型会生成指定数量的不同序列。这对于希望得到多种可能输出的场景是有用的。
penalty:这个参数用于控制生成文本中的重复性。值越大,生成的文本中的重复内容就越少。调整此参数可以影响生成文本的多样性和唯一性。
top_k:在生成过程中,模型会在每个时间步骤为每个可能的下一个词赋予一个分数。top_k用于限制在每个时间步骤中,模型只考虑分数最高的k个词。如果top_k设置的太小,可能会导致生成的文本过于单一;设置的太大,可能导致生成的文本缺乏连贯性。
top_p:这也是一种限制模型考虑的可能下一个词的方法,不同的是,它是基于分数的累积概率而不是个数。即在每个时间步骤中,模型会考虑到使得下一个词的分数的累积概率超过top_p的最小集合。这种方法又被称为nucleus sampling。它可以增加生成文本的多样性。
调整这些参数可以影响生成的质量。例如,适当增大penalty可以减少生成文本中的重复;合理设置top_k和top_p可以影响生成文本的多样性和连贯性。但需要注意的是,没有一组适合所有场景的最优参数,需要根据具体任务和数据进行尝试和调整。
字数限制:请注意,该参数为内容的生成最高字数,如果觉得模型生成的字数低,请调整该参数,比如,字数限制是800,那么模型生成的字数绝对不会超过800字。
字数限制还有个问题请注意,模型的生成字数长度多少,取决于训练语料的字数,如果您的训练语料字数普遍只有三四百字,那么模型最终生成的字数也是三四百字。标准模型则可以最高支持3倍以上的字数生成。
最简单的调整参数教学:
penalty:你就把它看成,控制生成内容的重复性的,减少它,则会让内容有更多重复的语句,词语出现。
top_k:这个参数是调整生成的内容的随机性的,调整大,则会出现随机性越大,越能拓展你的学习语料。调小则会更贴近你的训练样本。
top_p:这个参数也是调整生成内容的随机性,只不过它是控制概率采样的,也就是生成推理时候,预测下一个组词命中我们模型词典数据。
减少top_k并增加top_p参数值,模型的输出会变得更有确定性,更接近它在训练数据中看到学习的内容。
软件操作教程:
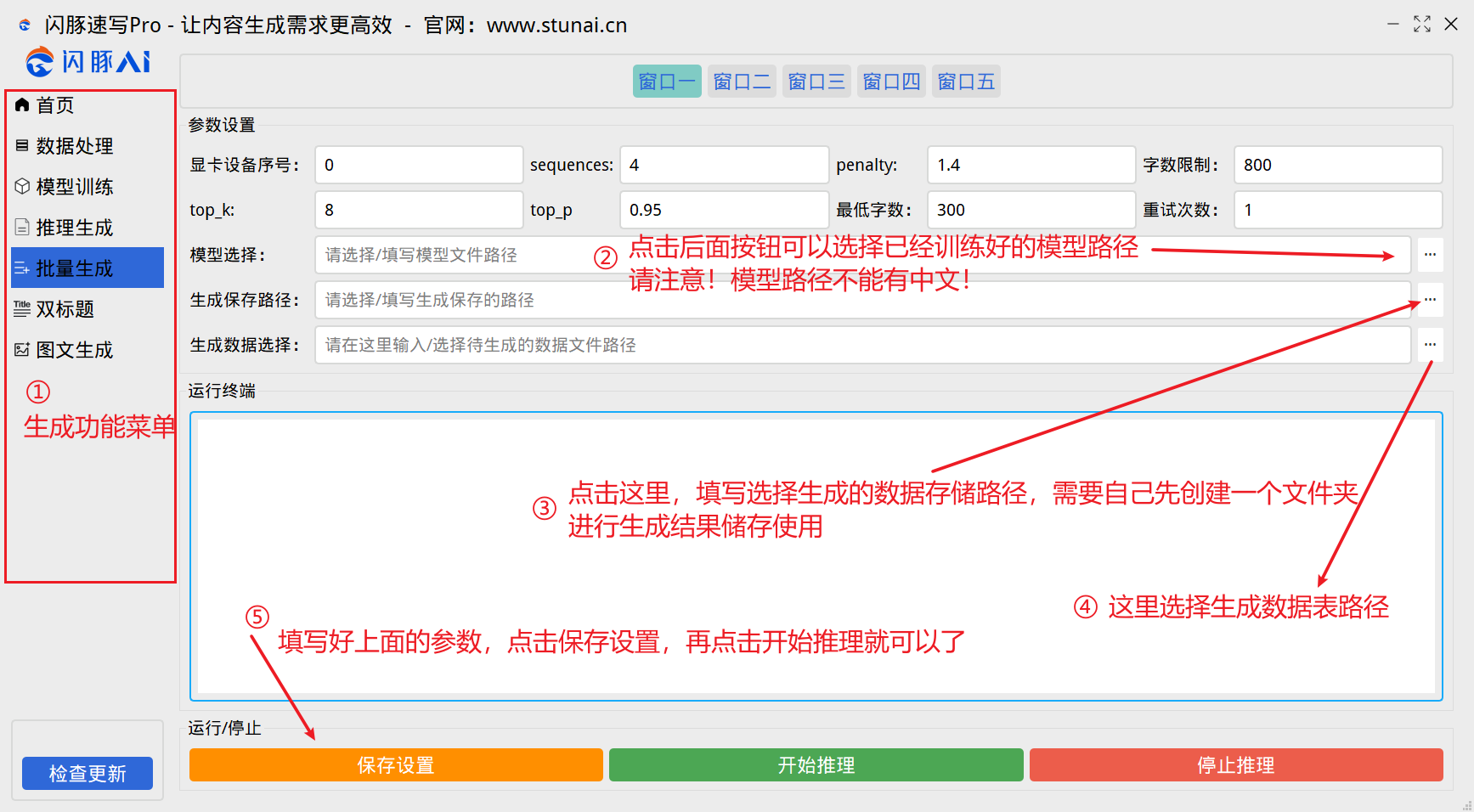
生成数据表格式要求:
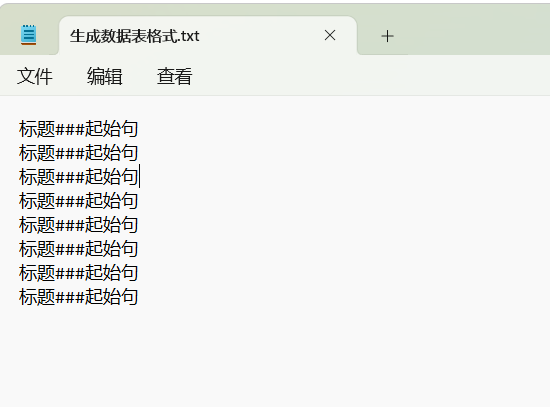
如果你只有关键词,可以使用下面的工具进行数据表转换

工具下载链接:
https://www.stunai.cn/app/75359.html
推荐使用完成的标题和起始句(文章的第一句话),这种方式去引导模型生成内容,质量会更好。

