


一、参数的优化调整
关于本次更新Pro1.9.1,优化调整了Max len参数说明。请使用者按以下解释指导进行训练操作。
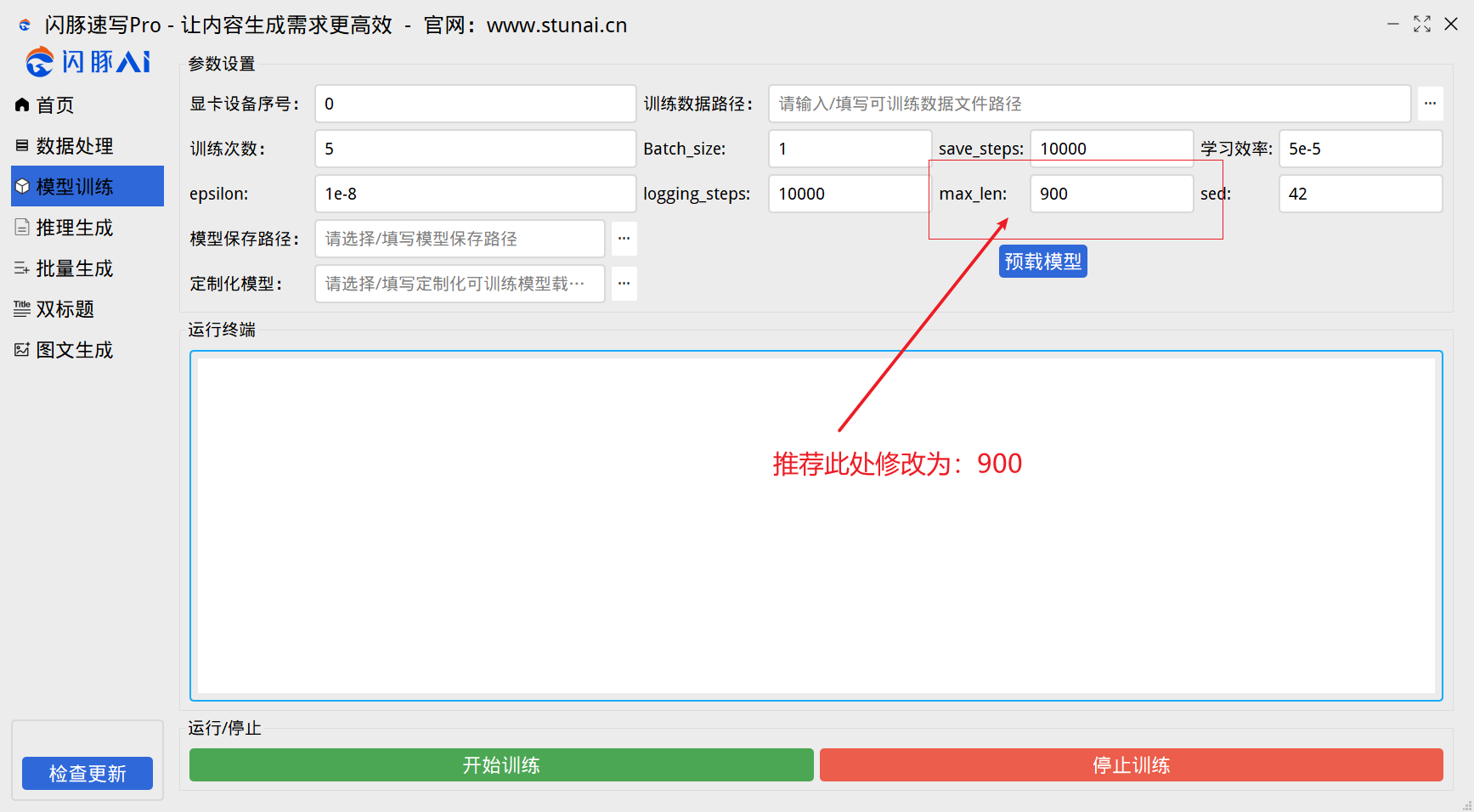
本次调整Max len参数,在安装包1.9.1会自动调整900。(原参数为1024)
如已安装其他版本的包,本次使用在线更新,该参数无法覆盖,需手动修改为“900”参数值,如下图展示:
原因如下:
原本参数为1024,指的是1024的Token词汇长度进行输入。在某些情况下,当显存为24Gb时(24576MiB),正常训练使用,会占用到“24000MiB”的显存,可能仅剩下:“576MiB”,也就是剩下很少很少,只要有其他应用占用一下GPU的显存,可能就导致训练过程中出现“OMM”情况,也就是:“显存爆了,显存不够用”,就导致训练出错。
关于Token的词汇,您可以简单理解为中文长度就行。因为训练模型,在我们中央验证中心服务器中,存储了预训练模型的词汇表,也就是您训练的时候,对数据预处理后,可训练文件Json中的所有文字,在训练开始时,会对模型词汇表进行匹配,如正确匹配则进行分词训练,这个步骤是个复杂的NLP知识理论,您不需要了解很深,如对此感兴趣,可自行查阅通用模型训练相关的学习资料。
本次优化了训练架构,推荐所有用户,将该参数调整为:900,进行训练,这样能更大的留存1~2Gb的显存进行缓冲。
请注意:原参数为1024,现调整900,对模型的影响很小很小。不比太过于担心模型的质量会受到影响。反而调整了该参数,能更稳定的提升模型训练过程。此步骤是极其值得推荐操作的。
二、模型的选择使用
推荐24Gb显卡的用户们,也可以尝试使用Small模型,Small模型并不比标准模型差很多。使用Small模型,训练会更快。
Small模型与标准模型的能力差距如下:
标准模型:训练次数少,能达到不错的效果
| 标准模型 | Small模型 | |
| 训练时长 | 推荐训练5轮左右就可用 | 推荐训练30~50轮左右 |
| 训练速度 | 3090每秒2~4条数据训练 4090每秒5~8条数据训练 | 3090每秒10~15条数据训练 4090每秒20~25条数据训练 |
| 模型能力 | 支持语料长度3倍生成输出 | 对超越语料原始字数生成输出不太好 |
| 模型大小 | 成品模型大约在6Gb左右 | 成品模型大约在2Gb左右 |
| 知识能力 | 能承载百万级以上语料训练 | 仅承载50万级语料以下训练 |
推荐用户们可以尝试使用Small模型进行体验使用。


内容很实用
学习到了