

本工具主要作用:
对长文本进行切割,当采集整理回来的数据较长,或者以整本书,或者其他长文本资料,需要用于做语料训练的情况下,想让模型完整的学习长文本的内容。则需要对长文本进行拆分。
本工具会以闪豚速写Pro训练要求对长文本进行拆分。
请注意:一定要把语料先清洗干净后,再用本工具,本工具仅只会对长文本拆分,不会进行其他操作。所以使用前,需要确认排版,内容是否正确。
本工具拆分会以1000字进行截断拆分,会以完成的一句话为结尾,并不会拆分后导致长文本题不对文的情况。
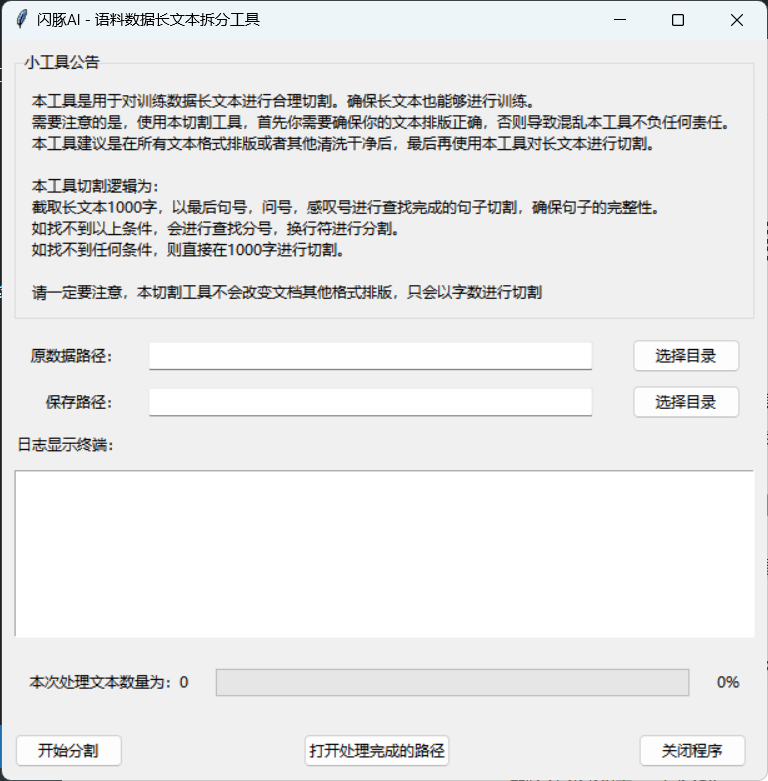
切分完效果如下:
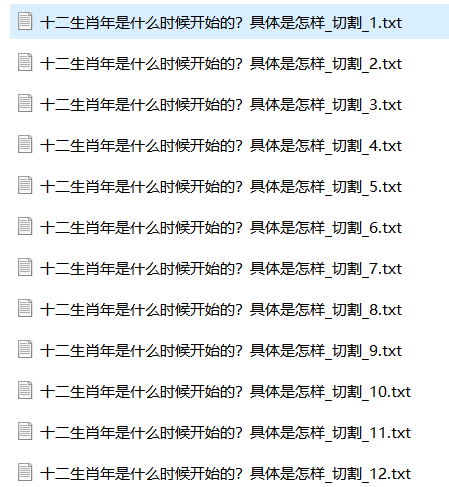
切分完成的数据,每个文件的第一行还是原标题,所以处理成训练数据的JSON文件时候,直接可以加入处理就行,这样就能确保模型能学习到该标题下能关联更长的数据。

